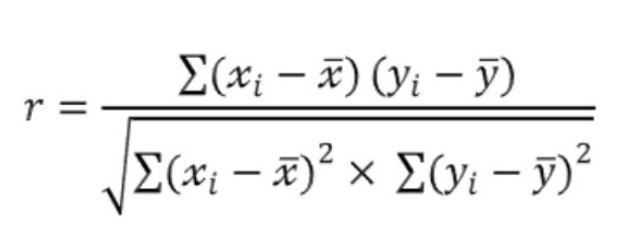- 어떤 아이템에 대해 비슷한 취향을 가진 사람들은 다른 아이템 또한 비슷한 취향을 가질 것이라 가정함
ex) user 1에게 추천을 해 주기 위해서는 각 사용자와의 유사성을 계산하고 해당 사용자가 좋아한 컨텐츠 추천
- user 4, user3 참고해 추천
* 유사도 지표 - CF에서 사용자간 유사도를 구하는 것이 핵심
1) 상관계수
1. 가장 이해하기 쉬운 유사도 2. -1 ~ 1 사이 값
2) 코사인 유사도
1. 협업 필터링에서 가장 널리 쓰이는 유사도 2. 각 아이템 => 하나의 차원, 사용자의 평가값 => 좌표값 3. 두 사용자의 평가값 유사 => theta는 작아지고, 코사인 값은 커짐. 4. -1 ~ 1 사이의 값 5. 데이터 이진값(binary) => 타니모토 계수(tanimoto coefficient) 사용 권장
3) 자카드 계수
1. 타니모토 계수의 변형 => 자카드 계수 2. 이진수 데이터 => 좋은 결과
* 기본 CF 알고리즘
1) 모든 사용자 간 평가의 유사도 계산 2) 추천 대상과 다른 사용자간 유사도 추출 3) 추천 대상이 평가하지 않은 아이템에 대한 예상 평가값 계산 (평가값 = 다른 사용자 평가 X 다른 사용자 유사도) 4) 아이템 중에서 예상 평가값 가장 높은 N개 추천
- RMSE 이웃 간의 유사도를 평가하고, 이 정보가 저장된 행렬을 기반으로 코사인 유사도로 점수를 구함
- 조금 개선된 결과
- 피어슨 상관관계를 사용하여도 됨
* 이웃을 고려한 CF
단순 CF 알고리즘 개선 방법 1. K Nearest Neighbors (KNN) 방법
사용자 맞춤 추천에 KNN 사용 :
user_id =729, item = 5, neighbors= 30
* 최적의 이웃 크기 결정하는 법
- 일정 시점까지 증가하다가 일정 시점 이후 감소하는 정확도
- 집단의 크기 = 전체 집단일 경우 인기제품 방식과 동일함 (클수록 오버피팅)
- 반면, 적을수록 데이터에 대한 신뢰성 떨어짐 (언더피팅)
neighbors 수 바꿔가며 결과 비교:
* 사용자의 평가 경향을 반영한 모델
- 사용자에 따라 동일한 점수가 다른 의미를 지닐 수도 있기 때문에 사용자의 평가 경향 고려
계산 과정:
1) 각 사용자 평점평균 계산 2) 평점 -> 각 사용자의 평균에서의 차이로 변환 (평점 – 해당 사용자의 평점 평균) 3) 평점 편차의 예측값 계산 (평가값 = 평점편차 x 다른 사용자 유사도) 4) 실제 예측값 = 평점편차 예측값 + 평점평균
2. Thresholding 방법
** Matrix Factorization(MF) 기반 추천
1) 메모리 기반 알고리즘:
- CF 필터링이 이 중 하나, 개별 인물에 집중
- 단, 시간이 너무 오래 걸림
- 개별적인 그룹을 경향성, 즉 약한 신호를 잘 못 잡음
2) 모델 기반 알고리즘
- 미리 모델 구성
- 필요 시 데이터를 모델에 적용
- 약한 신호에 상대적으로 강함
- 모델 구성 시 시간이 오래 걸림
MF 필터링
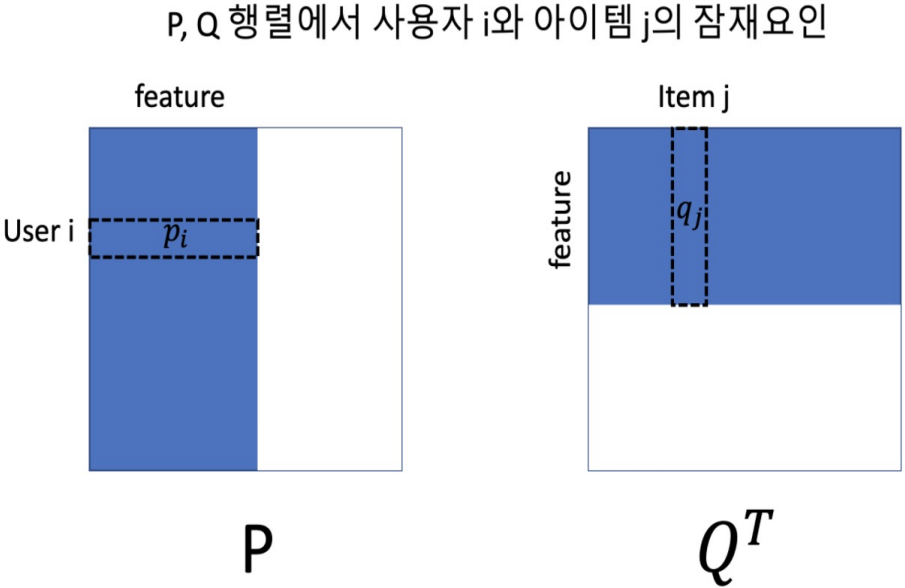
- 1개의 행렬을 사용자와 아이템으로 된 2개의 행렬로 분해함
- 각각이 사용자 잠재 요인 행렬과 아이템 잠재 요인 행렬
- P: M*K
- Q: K*N
- R: M*N
- 4명의 사용자, 4개의 영화에 대해 요인 2개가 있다고 가정한 상태
- 2개의 표를 보고 아래와 같이 2차원 공간에서 해석할 수 있음
- 따라서 행렬 연산을 통해 아래 표와 같이 사용자별 각 영화에 대한 예측평점을 구할 수 있음
기본적인 MF 알고리즘 프로세스
1) 잠재 요인 K 선택
2) P, Q 행렬 초기화
3) 기준 오차 도달 확인
4) R- R(pred) 간 오차를 계산하고, P, Q 수정
>> 어떻게 수정할 것인가? : SGD
5) 모든 R(pred) 계산
* SGD(Stochastic Gradient Decent)를 사용한 MF 알고리즘
- 예측 오차를 구하기 위해서 p, q를 업데이트함
- 에러 최소화 << 편미분하여 e를 최소화하는 p, q 값 찾기
- 전체 평균에서 사용자 평가 경향을 빼 주는 프로세스도 거침
classMF():
def__init__(self,ratings,hyper_params):
self.R = np.array(ratings)
self.num_users, self.num_items = np.shape(self.R) #사용자, 아이템 수
self.K = hyper_params['K'] # 잠재요인
self.alpha = hyper_params['alpha'] #학습률
self.beta = hyper_params['beta'] #정규화 계수
self.iterations = hyper_params['iterations']
self.verbose = hyper_params['verbose']
defRMSE(self):
xs, ys = self.R.nonzero()
self.predictions = []
self.errors = []
for x, y inzip(xs, ys):
prediction = self.get_prediction(x,y)
self.predictions.append(prediction)
self.errors.append(self.R[x,y] - prediction) # 실제-예측값 행렬에 추가
self.predictions = np.array(self.predictions)
self.errors = np.array(self.errors)
return np.sqrt(np.mean(self.errors**2))
deftrain(self):
self.P = np.random.normal(scale=1./self.K,
size = (self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K,
size = (self.num_items, self.K)) # 각각 초기화
self.b_u = np.zeros(self.num_users)
self.b_d = np.zeros(self.num_items) # 평가경향 초기화
self.b = np.mean(self.R[self.R.nonzero()])
rows, columns = self.R.nonzero()
self.samples = [(i,j,self.R[i,j]) for i, j inzip(rows, columns)]
training_process = []
for i inrange(self.iterations):
np.random.shuffle(self.samples)
self.sgd()
RMSE = self.RMSE()
training_process.append((i+1, RMSE)) # 각각 가중치 업데이트
ifself.verbose:
if (i+1) % 10 == 0:
print('Iteration : %d ; train RMSE = %.4f' % (i+1, RMSE)) # 10회 반복마다 학습 결과 출력