[목차]
10-1) 다양한 종류의 시계열 딥러닝
10-2) 온도 예측 문제
10-3) 순환 신경망 이해하기
10-4) 순환 신경망의 고급 사용법
10-1) 다양한 종류의 시계열 딥러닝
시계열 데이터: 일정한 간격으로 측정하여 얻은 데이터
ex) 자연 현상(지진 활동 등), 인간의 활동 패턴(웹 사이트 방문자, 카드 거래 변화 등)
>> 시스템 역학에 대한 이해 필요
작업 종류
1) 예측: 현 시점의 데이터 다음에 일어날 변화를 예측
>> 가장 일반적인 시계열 관련 작업
2) 분류: 하나 이상의 범주형 레이블을 시계열에 부여 (봇/인간 구분 등)
3) 이벤트 감지: 연속된 데이터 스트림에서 예상되는 특정 이벤트를 식별 (인공지능의 특정 단어 감지 등)
4) 이상치 탐지: 연속된 데이터 스트림에서 발생하는 비정상적인 현상을 감지
특징: 다양한 분야에 특화된 데이터 표현 기법 볼 수 있음
(예시: 푸리에 변환 > 주기와 진동이 특징은 소리, 뇌파 등 데이터에 사용함)
10-2) 온도 예측 문제
* 순환 신경망으로 시계열 예측하는 예제
데이터: 14개의 기후 관측치(온도 기압, 풍향 등)이 10분 단위로 기록되어 있는 데이터
타깃: 미래의 온도
import os
fname = os.path.join("jena_climate_2009_2016.csv")
with open(fname) as f:
data = f.read()
lines = data.split("\n")
header = lines[0].split(",") // 데이터와 헤더를 분리함
lines = lines[1:]
print(header)
print(len(lines))
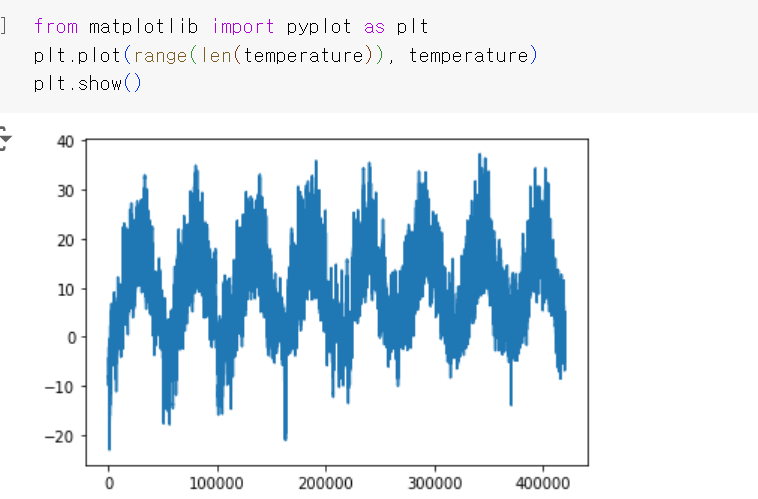
전체를 넘파이 배열로 변환한 후 예측할 타깃인 온도만 따로 시각화하면 이러한 결과를 얻을 수 있다.
그래프를 보았을 때 온도가 어느 정도 주기성을 띈다는 것을 확인할 수 있음.
*** 시계열 데이터: 주기성은 시계열 데이터에서 매우 일반적인 성질 > 이러한 패턴 찾아야 함
num_train_samples = int(0.5 * len(raw_data))
num_val_samples = int(0.25 * len(raw_data))
num_test_samples = len(raw_data) - num_train_samples - num_val_samples
print("num_train_samples:", num_train_samples)
print("num_val_samples:", num_val_samples)
print("num_test_samples:", num_test_samples)
** 셔플하면 안 됨
*** 검증 데이터와 테스트 데이터가 훈련 데이터보다 최신 것이어야 함
(예측 문제이므로 순서 매우 중요)
모든 데이터가 수치형이므로 별다른 전처리 없이 정규화
sampling_rate = 6 // 데이터 용량 축소 위해 10분 단위 > 1시간 단위 축소
sequence_length = 120
delay = sampling_rate * (sequence_length + 24 - 1)
batch_size = 256
train_dataset = keras.utils.timeseries_dataset_from_array( // 학습 데이터
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=0,
end_index=num_train_samples)
val_dataset = keras.utils.timeseries_dataset_from_array( // 검증 데이터
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples,
end_index=num_train_samples + num_val_samples)
test_dataset = keras.utils.timeseries_dataset_from_array( // 테스트 데이터
raw_data[:-delay],
targets=temperature[delay:],
sampling_rate=sampling_rate,
sequence_length=sequence_length,
shuffle=True,
batch_size=batch_size,
start_index=num_train_samples + num_val_samples)
keras.utils.timeseries_dataset_from_array(): 각 데이터셋 생성에 활용된 케라스 유틸 함수.
샘플 데이터 배열을 생성해 다음 스템에 대한 시계열 예측 수행함
[상식 수준의 기준점 넘기]
- 정상적으로 예측이 가능한 문제인지 확인하기 위해 학습 검증 지표 설정
(ex) 모두 비율이 높은 어떠한 클래스에 속한다 예측하였을 때의 정확도)
* 이 경우에는 연속성/주기성이 있는 데이터이기 때문에 직전 일자 같은 시간의 기온과 동일하다고 예측하였을 때의 손실 값을 기준점으로 삼음
def evaluate_naive_method(dataset):
total_abs_err = 0.
samples_seen = 0
for samples, targets in dataset:
preds = samples[:, -1, 1] * std[1] + mean[1]
total_abs_err += np.sum(np.abs(preds - targets))
samples_seen += samples.shape[0]
return total_abs_err / samples_seen
print(f"검증 MAE: {evaluate_naive_method(val_dataset):.2f}")
print(f"테스트 MAE: {evaluate_naive_method(test_dataset):.2f}")
검증 MAE: 2.44
테스트 MAE: 2.62
>> 상식 수준의 기준점은 대략 손실 2.5 (MAE)
[기본적인 머신 러닝 모델 시도]
* 소규모 완전 연결 네트워크
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Flatten()(inputs)
x = layers.Dense(16, activation="relu")(x) // 1개 완전 연결 층
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_dense.keras", // 콜백을 지정하여 최상의 모델 저장
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_dense.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")
미분 가능하여야 하므로 손실은 MAE가 아닌 MSE 사용

> 상식 수준 기준점을 넘지 못하였음
사유 1) 가설 공간이 일부만 해당 모델이 표현 가능 > 최적의 솔루션 도출 어려움
사유 2) 좋은 특성 공학, 문제와 관련한 아키텍처 구조 활용 필요
[1D 합성곱 모델 시도]
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Conv1D(8, 24, activation="relu")(inputs) // 초기 윈도우 길이는 24로 지정
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 12, activation="relu")(x)
x = layers.MaxPooling1D(2)(x)
x = layers.Conv1D(8, 6, activation="relu")(x)
x = layers.GlobalAveragePooling1D()(x)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_conv.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_conv.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")
입력 시퀀스가 주기를 가져 날짜별로 합성곱 표현 재사용 가능함
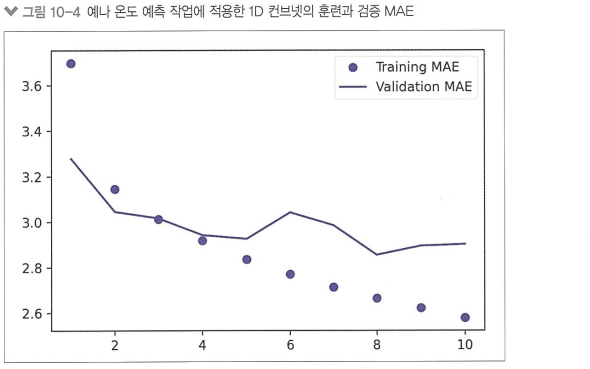
> 2.5보다 높은 손실 : 상식 수준 기준점 넘지 못함
사유1) 날씨 데이터는 평행 이동 불변성 가정을 따르지 않음 > 특정 시간 범위에서만 평행 이동 불변성 가짐
(ex) 아침 > 아침)
사유2) 최대 풀링, 전역 평균 풀링 층이 데이터 안 순서 정보 삭제함
[첫 번째 순환 신경망]
순환 신경망에 인과 관계와 순서가 의미 있는 시퀀스 데이터 사용
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.LSTM(16)(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_lstm.keras")
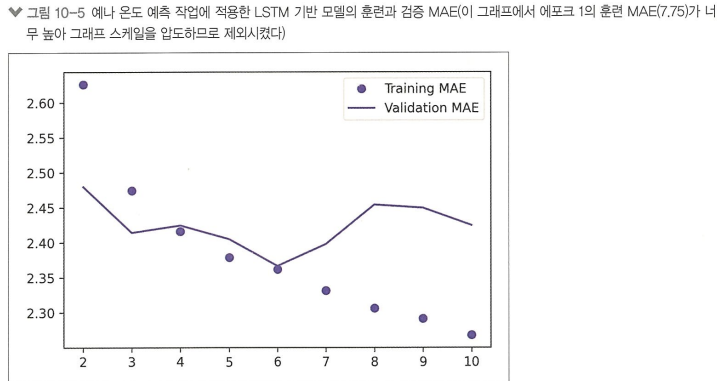
>> 상식 수준 기준점이 되는 2.5를 넘김 (LSTM)
10-3) 순환 신경망 이해하기
피드포워드 네트워크: 입력 간에 유지되는 상태 없음, 데이터를 펼쳐서 하나의 큰 벡터로 만들어 처리
> 앞선 데이터 기반 정보 업데이트 불가
(ex) 밀집 연결 네트워크, 컨브넷)
순환 신경망: 과거 정보를 사용하여 구축, 새롭게 얻은 정보를 계속 업데이트함
특징: 시퀀스를 하나의 데이터 포인트로 간주, 시퀀스의 원소를 순회하면서 지금까지 처리한 정보를 상태에 저장함
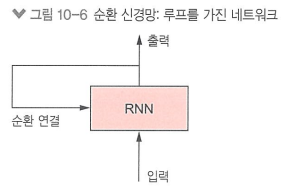
과정:
초기 상태 = 0
for(매 시퀀스 마다){
output = dot (가중치 행렬 W, 입력) + b + dot ( U, 편향 벡터 )
상태 = output // 상태를 업데이트함
}
import numpy as np
timesteps = 100 // 입력 시퀀스 타임스텝 수
input_features = 32 // 입력 차원
output_features = 64 // 출력 차원
inputs = np.random.random((timesteps, input_features))
state_t = np.zeros((output_features,))
W = np.random.random((output_features, input_features))
U = np.random.random((output_features, output_features)) // 랜덤한 가중치 행렬 생성
b = np.random.random((output_features,))
successive_outputs = []
for input_t in inputs:
output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b)
successive_outputs.append(output_t) // 출력을 리스트에 저장함
state_t = output_t // 상태 업데이트
final_output_sequence = np.stack(successive_outputs, axis=0) // (타임스텝, 출력 특성) > 랭크 2 텐서
> 입력과 현재 상태 (이전 스텝의 출력) 을 연결하여 현재 출력 얻음, 활성화 함수 사용해 비선형성 추가
> 이를 바탕으로 시퀀스마다 상태 업데이트함
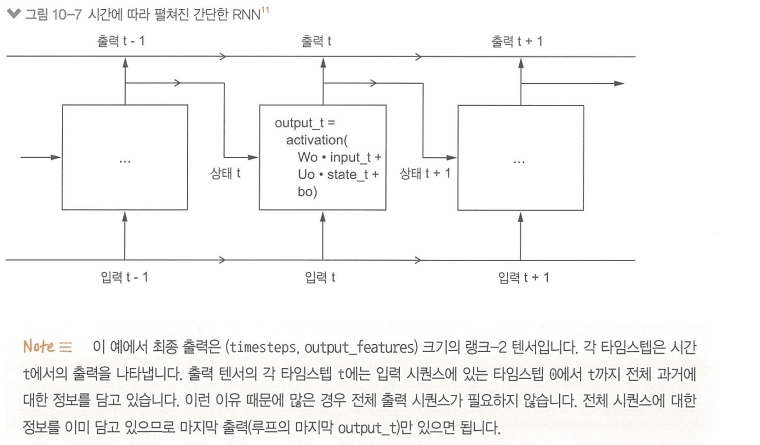
[SimpleRNN 모델 (케라스의 순환 층)]
앞선 모델과의 차이: 시퀀스가 아니라 시퀀스의 배치 단위로 처리함.
즉, 입력 : ( batch_size, timesteps, input_features ) 형태여야 처리 가능함
* 시퀀스 = None 으로 지정 시 임의 길이 처리 가능. 단, model.summary() 메소드를 사용하기 위해서는 입력 지정하여야 함
inputs = keras.Input(shape=(steps, num_features))
x = layers.SimpleRNN(16, return_sequences=True)(inputs)
x = layers.SimpleRNN(16, return_sequences=True)(x)
outputs = layers.SimpleRNN(16)(x)
단점 ) 긴 시간에 걸친 의존성은 학습할 수 없음 (그레이디언트 소실 문제)
> 층 쌓일수록 오차가 그레이디언트 정로량을 압도함
[LSTM 모델]
> 그레이디언트 소실 문제 해결하기 위해 고안된 모델
1. 나중을 위해 정보를 저장하고, 정보를 여러 타임스템에 걸쳐 나름
2. 추출된 정보가 필요한 시점의 타임스텝으로 이동함
3. 처리 과정에서 오래된 시그널이 점차 소실되는 것을 막음
구조:

이동 상태 c_t: 타임스텝을 거쳐 정보를 나르는 데이터 흐름, 입력 연결과 순환 연결(상태)에 연결됨
출력_t = 활성화 함수( dot (가중치 행렬 W, 입력) + b ) + dot ( U, 편향 벡터 )
3개의 다른 변환이 각자 자신만의 가중치 행렬을 가짐
> 이 흐름이 다음 출력과 상태를 조절함
식으로 표현: c_t+1 = i_t*k_t + c_t* f_t
c_t* f_t: 데이터 흐름에서 관련이 없는 정보들을 의도적으로 삭제함
i_t*k_t : 현재에 대한 정보 제공, 이동 트랙을 새로운 정보로 업데이트함
>> 과거 정보까지 carry로 주입해 그레이디언트 소실 해결!
10-4) 순환 신경망의 고급 사용법
1: 순환 드롭아웃 사용 (과대적합 방지용)
일반 드롭아웃: 입력 층의 유닛을 랜덤하게 꺼 학습에 도움이 되지 않음
순환 드롭아웃: 동일한 드롭아웃 마스크를 모든 타임스텝에 적용 (타임스텝마다 동일한 패턴으로 유닛을 드롭아웃시킴) > 네트워크가 학습 오차를 타임스텝에 걸쳐 적절히 전파 가능
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
# 훈련 속도를 놓이기 위해 순환 드롭아웃을 제외합니다.
#x = layers.LSTM(32, recurrent_dropout=0.25)(inputs)
x = layers.LSTM(32)(inputs)
x = layers.Dropout(0.5)(x) // 입력에 대한 드롭아웃 비율
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_lstm_dropout.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=50, // 학습 오래 걸림, 따라서 에포크 2배로 늘림
validation_data=val_dataset,
callbacks=callbacks)

2: 스태킹 순환 층
: 유닛의 개수를 늘리거나 층을 더 많이 추가해 더 강력한 순환 네트워크 만듬
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
# 훈련 속도를 놓이기 위해 순환 드롭아웃을 제외합니다.
# x = layers.GRU(32, recurrent_dropout=0.5, return_sequences=True)(inputs)
# x = layers.GRU(32, recurrent_dropout=0.5)(x)
x = layers.GRU(32, return_sequences=True)(inputs) // 전체 시퀀스
x = layers.GRU(32)(x) // 추가된 층
x = layers.Dropout(0.5)(x) // 드롭아웃 적용
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
callbacks = [
keras.callbacks.ModelCheckpoint("jena_stacked_gru_dropout.keras",
save_best_only=True)
]
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=50,
validation_data=val_dataset,
callbacks=callbacks)
model = keras.models.load_model("jena_stacked_gru_dropout.keras")
print(f"테스트 MAE: {model.evaluate(test_dataset)[1]:.2f}")
단, 이 예제에 한해서는 크게 성능 개선 x
3: 양방향 순환 층
타임 시퀀스 반대 방향으로도 학습 진행
> 단방향 RNN이 놓치기 쉬운 패턴 감지할 수 있음
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Bidirectional(layers.LSTM(16))(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset)
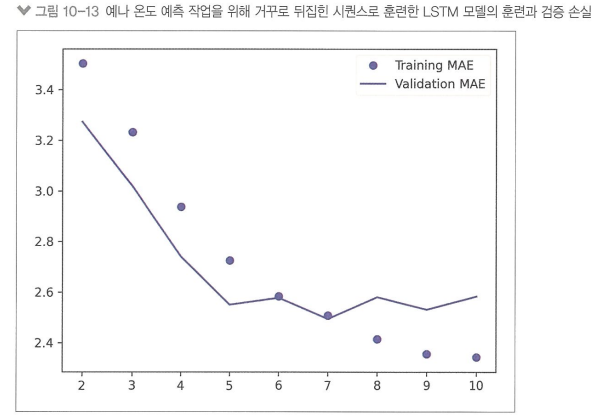
단, 이 예제에 한해서는 성능이 상식 수준 기준점보다도 떨어진 것 확인할 수 있음
이유 : 과거 정보를 중요하게 처리한 반대 방향 RNN이 모델 학습 결과에 영향을 미쳐서
> 최근 정보일수록 예측에 크게 영향을 미친다는 것 확인 가능
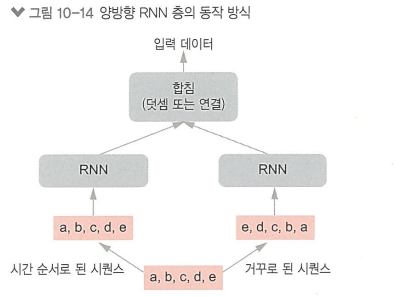
특징: 거꾸로 훈련한 시퀀스는 원래 시퀀스와는 다른 새로운 표현 학습함
> 자연어 처리 등 미래 시퀀스가 현재에 영향을 미칠 수 있는 케이스에서는 유용함!!



