[목차]
11-1) 자연어 처리 소개
11-2) 텍스트 데이터 준비
11-3) 단어 그룹을 표현하는 두 가지 방법: 집합과 시퀀스
11-4) 트랜스포머 아키텍쳐
11-5) 텍스트 분류를 넘어: 시퀀스-투-시퀀스 학습
11-1) 자연어 처리 소개
어셈블리어: 기계를 위해 고안된 언어
자연어: 사람의 언어
> 복잡하고, 모호하고, 불규칙함
불규칙적이기 때문에 언어 규칙 집합을 찾을 수 없음 > 데이터를 사용하여 이런 규칙을 찾는 과정을 자동화함
자연어 처리(NLP) : 입력을 언어로 받아 어떤 유용한 것을 반환하는 것
자연어 처리 예시
- 글의 주제 찾기(텍스트 분류)
- 텍스트에 부적절한 내용이 포함되어 있는지(콘텐츠 필터링)
- 텍스트가 긍정적/부정적인지 (감성 분석)
- 문장을 완성하기 위한 다음 단어 찾기(언어 모델링)
- 문장 번역
- 글을 하나의 문단으로 요약하기 (요약)
* 알고리즘은 언어를 사람처럼 이해하는 것이 아님, 통계적인 규칙을을 찾는 것!
11-2) 텍스트 데이터 준비
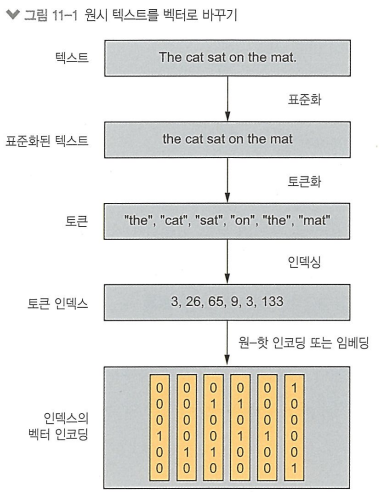
텍스트 벡터화: 텍스트를 입력으로 사용하기 위해 거쳐야 함
과정
1. 표준화: 모든 문자를 소문자로 바꾸고 구두점을 제거함
2. 토큰화: 텍스트를 토큰 단위로 분할함
3. 인덱싱: 모든 토큰을 수치 벡터로 표현함
1. 표준화
: 모든 문자를 소문자로 바꾸고 구두점을 제거함, 어간 추출
> 인코딩 차이를 모델이 고려하지 않고록 하는 기초적인 특성 공학
단, 이 과정에서 중요한 정보가 제거될 수 있으니 중요한 정보가 담긴 부분은 삭제하지 않고 별도의 토큰으로 취급해야 함
2. 토큰화
: 텍스트를 토큰 단위로 분할함 (토큰: 벡터화할 단위)
[종류]
단어 수준 토큰화 : 토큰이 공백 혹은 구두점으로 구분됨
N-그램 토큰화 : 토큰이 N개의 연속된 단어 그룹
문자 수준 토큰화 : 각 문자를 하나의 토큰으로 취급 (실제로 이를 잘 사용하진 않음)
[적용]
시퀀스 모델: 순서 정보를 고려하기 때문에 단어 수준 토큰화 사용
BoW 모델: 단어의 순서를 무시하고 집합으로 다루기 때문에 N-그램 토큰화 사용
3. 인덱싱
: 모든 토큰을 수치 표현으로 인코딩하는 과정
> 훈련 데이터에 있는 모든 토큰의 인덱스를 만들어 어휘 사전의 각 항목에 고유한 정수를 할당하는 방법
> 그 다음 이 벡터를 원-핫 벡터와 같은 벡터 인코딩을 거쳐 신경망에 주입
* 훈련 데이터에서 많이 등장하는 2~3만개의 단어로만 어휘 사전을 제한함
이유> 단어 개수 제한이 없으면 특성 공간이 너무 커지고 대부분 특성들은 정보가 없게 됨
단어에 매칭되는 인덱스가 없을 때 OOV 인덱스(1) 사용 , 무시해도 될 때 0 사용
* TextVectorization 층 사용하기
직접 인코딩하는 알고리즘 구현 시:
import string
class Vectorizer:
def standardize(self, text):
text = text.lower()
return "".join(char for char in text if char not in string.punctuation)
def tokenize(self, text):
return text.split()
def make_vocabulary(self, dataset):
self.vocabulary = {"": 0, "[UNK]": 1}
for text in dataset:
text = self.standardize(text)
tokens = self.tokenize(text)
for token in tokens:
if token not in self.vocabulary:
self.vocabulary[token] = len(self.vocabulary)
self.inverse_vocabulary = dict(
(v, k) for k, v in self.vocabulary.items())
def encode(self, text):
text = self.standardize(text)
tokens = self.tokenize(text)
return [self.vocabulary.get(token, 1) for token in tokens]
def decode(self, int_sequence):
return " ".join(
self.inverse_vocabulary.get(i, "[UNK]") for i in int_sequence)
vectorizer = Vectorizer()
dataset = [
"I write, erase, rewrite",
"Erase again, and then",
"A poppy blooms.",
]
vectorizer.make_vocabulary(dataset)
실제로는 케라스 TextVectorization 층 사용!
import re
import string
import tensorflow as tf
def custom_standardization_fn(string_tensor):
lowercase_string = tf.strings.lower(string_tensor) // 문자열을 소문자로 변환
return tf.strings.regex_replace( // 구두점 문자를 빈 문자열로 바꿈
lowercase_string, f"[{re.escape(string.punctuation)}]", "")
def custom_split_fn(string_tensor):
return tf.strings.split(string_tensor) // 공백을 기준으로 문자열을 나눔
text_vectorization = TextVectorization( // TextVectorization 층 사용
output_mode="int",
standardize=custom_standardization_fn,
split=custom_split_fn,
)
문자열 리스트로 이 층의 adapt() 메서드를 호출 가능
get_vocabulary() 메서드를 사용하여 계산된 어휘 사전을 추출할 수 있음.

(두번째 방법은 모델의 일부로 만드는 것)
11-3) 단어 그룹을 표현하는 두 가지 방법: 집합과 시퀀스
단어 순서 인코딩 > 단어를 문장으로 구성하는 방식이기에 인코딩 과정에서 매우 중요
[단어 그룹을 표현하는 방법 2가지]
1. 집합으로 표현 > BoW 모델: 단어의 순서를 무시하고 집합으로 다룸 / N-그램 토큰화 사용
2. 시퀀스로 표현 > 시퀀스 모델: 순서 정보를 고려 / 단어 수준 토큰화 사용
단어가 등장하는 순서대로 처리함 (RNN, 트랜스포머가 여기에 해당)
* 영화 리뷰 데이터셋 예제
from tensorflow import keras
batch_size = 32
train_ds = keras.utils.text_dataset_from_directory( // 훈련 셋
"aclImdb/train", batch_size=batch_size
)
val_ds = keras.utils.text_dataset_from_directory( // 검증 셋(전체 훈련 셋의 20%에 해당)
"aclImdb/val", batch_size=batch_size
)
test_ds = keras.utils.text_dataset_from_directory( // 테스트 셋
"aclImdb/test", batch_size=batch_size
)
(1) 단어를 집합으로 처리하기: BoW 방식
- 유니그램 : 단어 1개들의 집합으로 처리
text_vectorization = TextVectorization(
max_tokens=20000, // 20000개의 단어를 가진 어휘 사전
output_mode="multi_hot", // 멀티 핫 인코딩
)
text_only_train_ds = train_ds.map(lambda x, y: x)
text_vectorization.adapt(text_only_train_ds)
binary_1gram_train_ds = train_ds.map( // 훈련 셋 매핑
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
binary_1gram_val_ds = val_ds.map( // 검증 셋 매핑
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
binary_1gram_test_ds = test_ds.map( // 테스트 셋 매핑
lambda x, y: (text_vectorization(x), y),
num_parallel_calls=4)
from tensorflow import keras
from tensorflow.keras import layers
def get_model(max_tokens=20000, hidden_dim=16): // 모델 형태 정의
inputs = keras.Input(shape=(max_tokens,))
x = layers.Dense(hidden_dim, activation="relu")(inputs)
x = layers.Dropout(0.5)(x) // 드롭아웃 추가 (순환 드롭아웃 아님)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
return model
model = get_model() // 이전에 만든 get_model() 메서드 호출하여 모델 객체 정의
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("binary_1gram.keras",
save_best_only=True)
]
model.fit(binary_1gram_train_ds.cache(),
validation_data=binary_1gram_val_ds.cache(), // cache() 메서드를 호출하여 메모리에 캐싱함.
epochs=10, // 이렇게 하면 첫 에포크에서 한 번만 전처리하고 캐시에 있는
callbacks=callbacks) // 전처리된 텍스트를 재사용할 수 있음
model = keras.models.load_model("binary_1gram.keras")
print(f"테스트 정확도: {model.evaluate(binary_1gram_test_ds)[1]:.3f}")
테스트 정확도: 0.885
-바이그램 : 단어 2개의 집합으로 쪼개기
text_vectorization = TextVectorization(
ngrams=2, // 집합의 원소들은 단어 2개 이하
max_tokens=20000,
output_mode="multi_hot",
)
해당 부분만 다르게 정의하고 이후 모든 코드 동일
테스트 정확도: 0.898
> 큰 차이는 없으나, 약간 개선됨
- TF-IDF 인코딩을 사용한 바이그램
TF-IDF 인코딩 방식: 단어나 N-그램의 등장 횟수를 카운팅한 정보를 추가할 수 있음
(텍스트에 대한 단어의 히스토그램)
단어의 빈도는 텍스트의 의미에 중요함. 단, 의미 없이 많이 등장하는 단어가 있을 수도 있음.
> 단어의 등장 빈도 정보 + 텍스트에서 정보를 담고 있는 표현을 잘 잡도록 한 것이 ' TF-IDF 정규화'

text_vectorization = TextVectorization(
ngrams=2,
max_tokens=20000,
output_mode="tf_idf", // TextVectorization에서 TF-IDF 정규화 방식 적용하기
)
(2) 단어를 시퀀스로 처리하기: 시퀀스 모델 방식
> 순서 기반의 특성을 수동으로 만드는 대신 원시 단어 시퀀스를 모델에 전달하여 모델이 스스로 이런 특성을 학습하도록 하는 방법
입력 샘플을 정수 인덱스의 시퀀스로 표현 > 각 정수를 벡터로 매핑 > 벡터 시퀀스를 얻음
문제 : 원-핫 인코딩을 사용할 시 이전 모델모다 시간도 오래 걸리고 입력 크기도 커짐.
>> 따라서 특성 공간의 크기를 줄이는 단어 임베딩 필요!!
*** 단어 임베딩 : 모든 단어는 서로 독립적이지 않다는 특징을 고려해 사람의 언어를 구조적인 기하학적 공간에 매핑하는 것.

[차이]
원-핫 인코딩: 고차원 이진 벡터
단어 임베딩: 저차원의 부동 소수점 벡터 (많은 정보를 더 적은 차원으로 압축함)

예시와 같이 특성에 따라 단어 간의 유사도/비유사도 정보 표현 가능함
[방법]
-직접 훈련시키는 방법: 랜덤한 단어 벡터로 시작하여 신경망의 가중치 학습과 같은 방식으로 단어 벡터 학습시킴
* Embedding 층
(단어 인덱스 > Embedding 층 > 해당 단어 벡터) 과정 거침, 원핫벡터가 아닌 임베딩된 벡터 출력
embedding_layer = layers.Embedding(input_dim=max_tokens, output_dim=256) // 256차원으로 단어 매핑함
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = layers.Embedding(input_dim=max_tokens, output_dim=256)(inputs) // 임베딩 층 적용함
x = layers.Bidirectional(layers.LSTM(32))(embedded)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("embeddings_bidir_lstm.keras", // 모델 밑바닥부터 훈련하며 콜백 사용해 훈련 과정 체크함
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10, callbacks=callbacks)
model = keras.models.load_model("embeddings_bidir_lstm.keras")
print(f"테스트 정확도: {model.evaluate(int_test_ds)[1]:.3f}")
문제: 입력 시퀀스 길이가 짧을수록 입력 시퀀스 안 0들을 처리하면서 내부 상태에 저장된 정보 손실 일어남
** 마스킹 : 0으로 찬 패딩을 건너뛰게 해 주는 api
> mask[ i, t ] : 샘플 i의 타임스텝 t를 건너뛸지, 말아야 할 지 나타냄
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = layers.Embedding(
input_dim=max_tokens, output_dim=256, mask_zero=True)(inputs) // mask_zero 옵션을 True로 활성화하여
x = layers.Bidirectional(layers.LSTM(32))(embedded) // 마스킹을 추가한 임베딩 층 적용함
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("embeddings_bidir_lstm_with_masking.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=10, callbacks=callbacks)
model = keras.models.load_model("embeddings_bidir_lstm_with_masking.keras")
print(f"테스트 정확도: {model.evaluate(int_test_ds)[1]:.3f}")
테스트 정확도 : 88% > 조금 향상
- 사전 훈련된 단어 임베딩: 미리 계산된 임베딩 공간의 임베딩 벡터를 로드
GloVe 단어 임베딩 파일 파싱하고, 임베딩 행렬 만들어 모델에 적용 가능
embedding_dim = 100
vocabulary = text_vectorization.get_vocabulary()
word_index = dict(zip(vocabulary, range(len(vocabulary))))
embedding_matrix = np.zeros((max_tokens, embedding_dim))
for word, i in word_index.items():
if i < max_tokens:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector // 훈련된 임베딩 벡터를 임베딩 행렬에 각각 추가함
embedding_layer = layers.Embedding(
max_tokens,
embedding_dim,
embeddings_initializer=keras.initializers.Constant(embedding_matrix), // 임베딩 행렬로 초기화함
trainable=False, // 훈련 중 표현 변경 하지 않음
mask_zero=True,
)
11-4) 트랜스포머 아키텍쳐
트랜스포머: 순환 층이나 합성곱 층 등을 사용하지 않고 '뉴럴 어텐션' 이라는 메커니즘 사용함
*** 셀프 어텐션 이해하기
- 모델에 주어지는 각 입력 정보에 주요도 할당하는 과정
- 관련성이 높은 특성은 점수가 높게, 관련성이 적은 특성은 점수가 낮게 계산

** 자연어 처리에서의 셀프 어텐션: 문맥 인식을 가능케 함
단어 임베딩을 통해 모든 단어와의 관계를 고정시키고, 이 관계를 이용해 중요한 정보나 표현에 높은 관련성 점수를 부여함
>> 주변 단어에 따라 단어의 벡터 표현을 다르게 표현함

1) 벡어와 문장에 있는 모든 다른 단어 사이 관련성 점수를 계산
2) 관련성 점수로 가중치를 두어 문장에 있는 모든 벡터의 합을 계산

넘파이 스타일의 의사 코드로 셀프 어텐션을 구현하면 다음과 같음
일반화된 셀프 어텐션: 쿼리-키-값 모델
outputs = sum(values * pairwise_scores(query, keys)) : 입력값과 관련성 점수를 계산한 값을 곱해 새 벡터를 만들고, 이를 다 더함
**멀티 헤드 어텐션 : 셀프 어텐션의 출력 공간이 독립적으로 학습되는 부분 공간으로 나뉨
> 인코더 부분은 텍스트 분류에 사용할 수 있음
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim // 입력 토큰 벡터의 크기
self.dense_dim = dense_dim // 내부 밀집 층의 크기
self.num_heads = num_heads // 어텐션 헤드의 개수
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim) // 멀티헤드 어텐션을 layer 층에 추가함
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization() // 층 정규화
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None): // call() 메서드에서 연산을 수행함
if mask is not None:
mask = mask[:, tf.newaxis, :] // Embedding 층에서 생성하는 마스크는 2D이지만 어텐션 층은
3D/4D이므로 랭크를 늘려줌
attention_output = self.attention(
inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self): // 모델을 저장할 수 있도록 직렬화를 구현함
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
* BatchNormalization은 시퀀스 데이터에 적합하지 않기 때문에 LayerNormalization 사용함
* LayerNormalization 층: 각 시퀀스를 독립적으로 정규화함. 시퀀스 안에서 데이터를 개별적으로 구하기 때문에 각 시퀀스 안에서의 의미관계 파악에 유리함

> 셀프 어텐션은 시퀀스 원소 쌍 사이의 관계에 초점을 맞춘 집합 처리 메커니즘임 > 원소의 위치 정보 파악은 불가함

트랜스포머는 원소의 위치 정보를 위치 인코딩을 통해 파악함 (모델에 위치 정보 수동으로 주입함)
* 위치 인코딩: 문장의 단어 위치 정보를 단어 임베딩에 추가해 구현함
먼저 단어 인덱스의 임베딩 벡터를 학습하는 것처럼 위치 임베딩 벡터를 학습시킴
서브클래싱으로 위치 임베딩 구현 시:
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs): // 시퀀스 길이를 미리 알아야 위치 임베딩 가능
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding( // 토큰 인덱스를 위한 Embedding 층 준비
input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim) // 토큰 위치를 위한 Embedding 층 준비
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions // 두 임베딩 벡터를 더함
def compute_mask(self, inputs, mask=None): // 입력에 있는 0 패딩을 무시할 수 있도록 마스킹을 추가해야 함
return tf.math.not_equal(inputs, 0) // comepute_mask() 프레임워크에 의해 자동 호출
def get_config(self):
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,
})
return config
vocab_size = 20000
sequence_length = 600
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs) // 위치 임베딩
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x) // 트랜스포머 인코더
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("full_transformer_encoder.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20, callbacks=callbacks)
model = keras.models.load_model(
"full_transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder,
"PositionalEmbedding": PositionalEmbedding})
print(f"테스트 정확도: {model.evaluate(int_test_ds)[1]:.3f}")
테스트 정확도 : 88.3% >> 성능 향상 (순서 중요)
** BoW 모델/ 시퀀스 모델 선택하는 법

> 샘플 수가 적고 샘플 길이가 길수록 시퀀스 모델 사용
> 샘플 수가 많고 샘플 길이 짧을수록 BoW 모델 사용
11-5) 텍스트 분류를 넘어: 시퀀스-투-시퀀스 학습
시퀀스-투-시퀀스 모델: 입력으로 시퀀스를 받아 이를 다른 시퀀스로 바꿈
예시: 기계 번역, 텍스트 요약, 챗봇, 텍스트 생성 등등
인코더: 모델이 소스 시퀀스를 중간 표현으로 바꿈
디코더: 이전 토큰과 인코딩된 소스 시퀀스를 보고 타깃 시퀀스에 있는 다음 토큰 i를 예측하도록 훈련

1. 인코더가 소스 시퀀스를 인코딩함
2. 디코더가 인코딩된 소스 시퀀스와 초기 시드 토큰을 사용하여 시퀀스의 첫 번째 토큰을 예측함
3. 지금까지 예측된 시퀀스를 디코더에 다시 주입하고 다음 토큰을 생성하는 식으로 종료 토큰이 생성될 때까지 반복함
** 기계 번역 예제: 영어 <ㅡ> 스페인어
1. 영어, 스페인어 각각 전처리 작업
2. 번역 작업을 위해 영어, 스페인어를 딕셔너리로 같이 매핑함
batch_size = 64
def format_dataset(eng, spa):
eng = source_vectorization(eng)
spa = target_vectorization(spa)
return ({
"english": eng,
"spanish": spa[:, :-1], // 입력과 타겟 길이 동일하게
}, spa[:, 1:]) // 한 스텝 앞의 스페인어 문장이 타깃이 됨
def make_dataset(pairs):
eng_texts, spa_texts = zip(*pairs)
eng_texts = list(eng_texts)
spa_texts = list(spa_texts)
dataset = tf.data.Dataset.from_tensor_slices((eng_texts, spa_texts))
dataset = dataset.batch(batch_size)
dataset = dataset.map(format_dataset, num_parallel_calls=4)
return dataset.shuffle(2048).prefetch(16).cache() // 속도 향상 위해 메모리에 캐싱
train_ds = make_dataset(train_pairs)
val_ds = make_dataset(val_pairs)
* RNN 이용 시 문제
1. 타깃 시퀀스가 항상 소스 시퀀스와 동일한 길이여야 함
2. 토큰 n 예측 위해 0~n-1 토큰만 참조함

>> 트랜스포머 아키텍쳐 사용 : 뉴럴 어텐션 이용하여 타깃 토큰과 나머지 토큰의 관련성 식별
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
def get_causal_attention_mask(self, inputs):
input_shape = tf.shape(inputs)
batch_size, sequence_length = input_shape[0], input_shape[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
mult = tf.concat(
[tf.expand_dims(batch_size, -1),
tf.constant([1, 1], dtype=tf.int32)], axis=0)
return tf.tile(mask, mult)
def call(self, inputs, encoder_outputs, mask=None):
causal_mask = self.get_causal_attention_mask(inputs)
if mask is not None:
padding_mask = tf.cast(
mask[:, tf.newaxis, :], dtype="int32")
padding_mask = tf.minimum(padding_mask, causal_mask)
attention_output_1 = self.attention_1(
query=inputs,
value=inputs,
key=inputs,
attention_mask=causal_mask)
attention_output_1 = self.layernorm_1(inputs + attention_output_1)
attention_output_2 = self.attention_2(
query=attention_output_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
)
attention_output_2 = self.layernorm_2(
attention_output_1 + attention_output_2)
proj_output = self.dense_proj(attention_output_2)
return self.layernorm_3(attention_output_2 + proj_output)



