[목차]
12-1) 텍스트 생성
12-2) 딥드림
12-3) 뉴럴 스타일 트랜스포머
12-4) 변이형 오토인코더를 이용한 이미지 생성
12-5) 생성적 적대 신경망
12-1) 텍스트 생성
순환 신경망으로 시퀀스 데이터를 생성하는 것
역사
2000 후반~2010: 펜 위치를 기록한 시계열 데이터를 사용하여 순환 네트워크와 완전 연결 네트워크를 혼합한 네트워크로 사람이 쓴 것 같은 손글씨 생성
2014: LSTM ~2016년에 주류가 됨
2017~2018: 트랜스포머 아키텍쳐 사용
언어 모델
- 토큰(단어 또는 글자)들이 주어졌을 때 다음 토큰을 예측하는 작업을 수행하는 모델
- 언어의 통계적 구조인 잠재 공간을 학습함
- 임의 길이의 시퀀스 생성
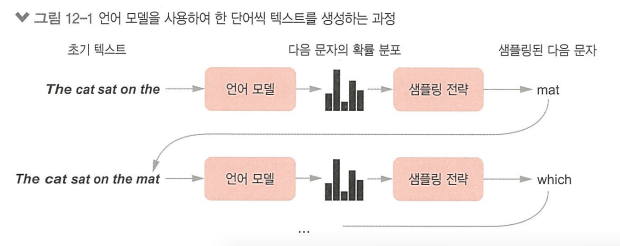
샘플링 전략
- 탐욕적 샘플링: 항상 가장 높은 확률을 가진 글자를 선택하는 방법
- 확률적 샘플링: 다음 단어를 확률 분포에서 샘플링하는 과정에 무작위성을 추가하는 것
무작위성은 모델에 창의성을 추가함 >> 무작위성 양 조절 필요! > 소프트맥스 출력을 이용
작은 엔트로피는 예상 가능한 결과를 만듬, 높은 엔트로피는 놀랍고 창의적인 시퀀스를 만듬
> 샘플링 과정에서 확률의 양을 조절하기 위해 소프트맥스 온도(temperature) 의 개념을 사용
소프트맥스 온도(temperature): 샘플링에 사용되는 확률 분포의 엔트로피를 나타냄 (0~2)

>> 갈수록 샘플링이 다양해짐
* 케라스를 이용한 텍스트 생성 모델 구현
from tensorflow.keras.layers import TextVectorization
sequence_length = 100 // 최대 시퀀스 길이 100으로 제한
vocab_size = 15000 // 자주 등장하는 15000개 단어만 사용
text_vectorization = TextVectorization(
max_tokens=vocab_size,
output_mode="int", // 정수 인덱스의 시퀀스를 반환
output_sequence_length=sequence_length,
)
text_vectorization.adapt(dataset)
트랜스포머 기반의 시퀀스-투-시퀀스 모델: n개 단어의 시퀀스를 입력으로 받아 n+1번째 단어를 예측하는 모델을 훈련함
이슈1) n개보다 적은 단어에서 훈련이 가능해야 함
이슈2) 훈련에 사용하는 많은 시퀀스는 중복되어 있음 > 이전에 처리한 시퀀스 중복 인코딩하게 됨
> 코잘 마스킹 추가: 인덱스 i에서 모델은 0~i의 단어들만 이용해서 i+1번째를 예측함
>> 생성 단계에서 하나의 입력만 주어져도 다음 단어에 대한 확률 분포를 만들 수 있음
>> n개의 토큰이 있을 때 n-1개의 문제를 해결함
* 텍스트 생성 콜백
import numpy as np
tokens_index = dict(enumerate(text_vectorization.get_vocabulary()))
def sample_next(predictions, temperature=1.0):
predictions = np.asarray(predictions).astype("float64") // 확률 분포 리턴하는 텍스트 생성기
predictions = np.log(predictions) / temperature
exp_preds = np.exp(predictions)
predictions = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, predictions, 1)
return np.argmax(probas)
class TextGenerator(keras.callbacks.Callback): // 텍스트 생성기
def __init__(self,
prompt,
generate_length,
model_input_length,
temperatures=(1.,),
print_freq=1):
self.prompt = prompt
self.generate_length = generate_length
self.model_input_length = model_input_length
self.temperatures = temperatures
self.print_freq = print_freq
def on_epoch_end(self, epoch, logs=None): // 각 에포크 끝에 학습된 결과 출력
if (epoch + 1) % self.print_freq != 0:
return
for temperature in self.temperatures:
print("== Generating with temperature", temperature)
sentence = self.prompt
for i in range(self.generate_length):
tokenized_sentence = text_vectorization([sentence])
predictions = self.model(tokenized_sentence)
next_token = sample_next(predictions[0, i, :], temperature)
sampled_token = tokens_index[next_token]
sentence += " " + sampled_token
print(sentence)
prompt = "This movie"
text_gen_callback = TextGenerator(
prompt,
generate_length=50,
model_input_length=sequence_length,
temperatures=(0.2, 0.5, 0.7, 1., 1.5)) // 온도를 다양하게 설정
temp = 0.2 >> 단조롭고 반복적

temp = 0.7 >> 어휘 사용 다양하고 자연스러움, 창의적

temp = 1.5 >> 랜덤함, 기본 구조 무너짐

* 딥러닝은 언어를 이해하는 것이 아니라 통계적 구조를 감지하는 것임
12-2) 딥드림
딥드림: 합성곱 신경망이 학습한 표현을 사용하여 예술적으로 이미지를 조작하는 기법
- 컨브넷 필터 시각화 기법과 거의 동일 (컨브넷 입력에 경사 상승법을 적용)
기본 아이디어
- 특정 필터가 아니라 전체 층의 활성화를 최대화
- 빈 이미지나 노이즈가 있는 이미지가 아닌 이미 가지고 있는 이미지를 입력으로 사용
- 시각 품질을 높이기 위해 여러 다른 스케일(옥타브) 로 처리
* 케라스 딥드림 구현

from tensorflow.keras.applications import inception_v3
model = inception_v3.InceptionV3(weights="imagenet", include_top=False)
사전 훈련된 모델과 테스트 이미지를 로딩함 (인셉션 V3 모델 사용)
layer_settings = {
"mixed4": 1.0,
"mixed5": 1.5,
"mixed6": 2.0,
"mixed7": 2.5,
}
outputs_dict = dict(
[
(layer.name, layer.output)
for layer in [model.get_layer(name) for name in layer_settings.keys()]
]
)
feature_extractor = keras.Model(inputs=model.inputs, outputs=outputs_dict)
딥드림 손실에 대한 각 층의 기여도 설정
def compute_loss(input_image):
features = feature_extractor(input_image) // 활성화를 추출
loss = tf.zeros(shape=())
for name in features.keys():
coeff = layer_settings[name]
activation = features[name]
loss += coeff * tf.reduce_mean(tf.square(activation[:, 2:-2, 2:-2, :])) // 경계 부분의 인공적 패턴을 피하기 위해 테두리가 아닌 픽셀만 손실 추가
return loss
손실을 계산함, 여러 층에 있는 필터 활성화를 동시에 최대화함
이때, 상위 층은 ImageNet에 있는 클래스로 보이는 시각 요소를 만들고, 하위 층은 기하학적 패턴을 만듬
>> 따라서 어떤 층을 선택했는지에 따라 만들어 내는 시각 요소에 큰 영향을 미침
import tensorflow as tf
@tf.function
def gradient_ascent_step(image, learning_rate):
with tf.GradientTape() as tape: // 현재 이미지에 대한 딥드림 손실의 그레이디언트를 계산
tape.watch(image)
loss = compute_loss(image)
grads = tape.gradient(loss, image)
grads = tf.math.l2_normalize(grads) // 그레이디언트 정규화
image += learning_rate * grads
return loss, image
def gradient_ascent_loop(image, iterations, learning_rate, max_loss=None): // 주어진 이미지 스케일에 대한 경사 상승법 수행
for i in range(iterations):
loss, image = gradient_ascent_step(image, learning_rate) // 딥드림 손실을 증가시키는 방향으로 반복적으로 이미지를 업데이트함
if max_loss is not None and loss > max_loss: // 손실이 일정 값을 넘으면 중지
break
print(f"... 스텝 {i}에서 손실 값: {loss:.2f}")
return image
각 옥타브에서 수행할 경사 상승법 단계
바깥쪽 루프에서 수행할 연산의 파라미터들
step = 20. // 경사 상승법 단계 크기
num_octave = 3 // 경사 상승법을 수행할 스케일 횟수
octave_scale = 1.4 // 연속적인 스케일 사이의 크기 비율
iterations = 30 // 스케일 단계마다 수행할 경사 상승법 단계 횟수
max_loss = 15. // 손실이 이보다 커질 시 중지할 중지 조건
이 외에 이미지 전처리, 후처리 등을 위한 여러 함수 유틸리티들을 호출해 사용
original_img = preprocess_image(base_image_path)
original_shape = original_img.shape[1:3]
successive_shapes = [original_shape]
for i in range(1, num_octave): // 이미지 크기를 여러 옥타브에서 계산
shape = tuple([int(dim / (octave_scale ** i)) for dim in original_shape])
successive_shapes.append(shape)
successive_shapes = successive_shapes[::-1]
shrunk_original_img = tf.image.resize(original_img, successive_shapes[0])
img = tf.identity(original_img) // 이미지를 복사
for i, shape in enumerate(successive_shapes): // 여러 옥타브에 대해 반복
print(f"{shape} 크기의 {i}번째 옥타브 처리")
img = tf.image.resize(img, shape)
img = gradient_ascent_loop( // 경사 상승법을 실행하고 딥드림 이미지를 수정함
img, iterations=iterations, learning_rate=step, max_loss=max_loss
)
upscaled_shrunk_original_img = tf.image.resize(shrunk_original_img, shape)
same_size_original = tf.image.resize(original_img, shape)
lost_detail = same_size_original - upscaled_shrunk_original_img // 두 이미지의 차이가 스케일 키웠을 때 손실된 디테일
img += lost_detail
shrunk_original_img = tf.image.resize(original_img, shape)
keras.utils.save_img("dream.png", deprocess_image(img.numpy()))
연속적인 여러 옥타브에 걸쳐 경사 상승법 수행함


손실로 사용할 층을 바꾸어 보았을 때 결과 크게 달라짐
상위 층: ImageNet에서 많이 등장하는 물체로 시각 패턴 만듬
하위 층: 지역적/ 덜 추상적임 > 기하학적 패턴 만듬
12-3) 뉴럴 스타일 트랜스포머
뉴럴 스타일 트랜스퍼: 타깃 이미지의 콘텐츠를 보존하면서 참조 이미지의 스타일을 타깃 이미지에 적용하는 분야 (스타일: 질감, 색깔 등 이미지에 있는 다양한 시각 요소)

구현 핵심: 딥러닝 알고리즘의 핵심과 동일(손실을 최소화하는 것)
손실 함수 = (참조 이미지와 생성 이미지 사이 스타일 손실) + (원본 이미지와 생성 이미지 사이 콘텐츠 손실)

content 함수는 이미지의 콘텐츠 표현 계산함
style 함수는 이미지의 스타일 표현 계산함
* 콘텐츠 손실
def content_loss(base_img, combination_img):
return tf.reduce_sum(tf.square(combination_img - base_img))
* 스타일 손실
def gram_matrix(x):
x = tf.transpose(x, (2, 0, 1))
features = tf.reshape(x, (tf.shape(x)[0], -1))
gram = tf.matmul(features, tf.transpose(features))
return gram
def style_loss(style_img, combination_img):
S = gram_matrix(style_img)
C = gram_matrix(combination_img)
channels = 3
size = img_height * img_width
return tf.reduce_sum(tf.square(S - C)) / (4.0 * (channels ** 2) * (size ** 2))
- 컨브넷이 참조 이미지에서 추출한 모든 특성을 잡아내야 함
- 층의 활성화 출력을 그람 행렬(= 층의 특성 맵들의 내적)을 스타일 손실로 사용
- 이러한 특성의 상관관계는 특정 크기의 공간적인 패턴 통계를 잡아냄
*요약
- 콘텐츠를 보존하기 위해 원본 이미지와 생성된 이미지 사이에서 상위 층의 활성화를 비슷하게 유지함. 이 컨브넷은 원본 이미지와 생성된 이미지에서 동일한 것을 보아야 함
- 스타일 보존 위해 저수준 층과 고수준 층에서 활성화 안에 상관관계를 비슷하게 유지함. 특성의 상관관계는 텍스처를 나타냄.
* 케라스로 뉴럴 스타일 트랜스퍼 구현
유틸리티 함수, 이미지 데이터 로딩 , 스타일/콘텐츠 손실 정의
model = keras.applications.vgg19.VGG19(weights="imagenet", include_top=False)
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
feature_extractor = keras.Model(inputs=model.inputs, outputs=outputs_dict)
> 사전 훈련된 컨브넷을 사용하여 중간 층 활성화를 반환하는 특성 추출 모델
네트워크 불러오기 (VGG19)
*총 변위 손실: 공간적 연속성 가지도록 돕고, 픽셀에 격자 무늬가 나타나는 것을 막음
def total_variation_loss(x):
a = tf.square(
x[:, : img_height - 1, : img_width - 1, :] - x[:, 1:, : img_width - 1, :]
)
b = tf.square(
x[:, : img_height - 1, : img_width - 1, :] - x[:, : img_height - 1, 1:, :]
)
return tf.reduce_sum(tf.pow(a + b, 1.25))
* 경사하강법 단계 설정
def compute_loss_and_grads(combination_image, base_image, style_reference_image):
with tf.GradientTape() as tape:
loss = compute_loss(combination_image, base_image, style_reference_image)
grads = tape.gradient(loss, combination_image)
return loss, grads
optimizer = keras.optimizers.SGD(
keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=100.0, decay_steps=100, decay_rate=0.96
)
)
base_image = preprocess_image(base_image_path)
style_reference_image = preprocess_image(style_reference_image_path)
combination_image = tf.Variable(preprocess_image(base_image_path))
iterations = 4000
for i in range(1, iterations + 1):
loss, grads = compute_loss_and_grads(
combination_image, base_image, style_reference_image
)
optimizer.apply_gradients([(grads, combination_image)])
if i % 100 == 0:
print(f"{i}번째 반복: loss={loss:.2f}")
img = deprocess_image(combination_image.numpy())
fname = f"combination_image_at_iteration_{i}.png"
keras.utils.save_img(fname, img)
* 특징
- 스타일 이미지의 텍스쳐가 두드러지고 비슷한 패턴이 많을 때 잘 작동함
- 고수준 이해나 추상적인 기교는 잘 수행하지 못함
- 느리지만 간단한 변환을 수행하기 때문에 작고 빠른 컨브넷을 사용하여 학습할 수 있음
12-4) 변이형 오토인코더를 이용한 이미지 생성
이미지 생성 : 잠재 공간을 학습하고 이 공간에서 샘플링하여 실제 사진에서 보간된 완전히 새로운 이미지를 만듬
생성자/디코더: 잠재 공간의 한 포인트를 입력으로 받아 이미지를 출력하는 모듈
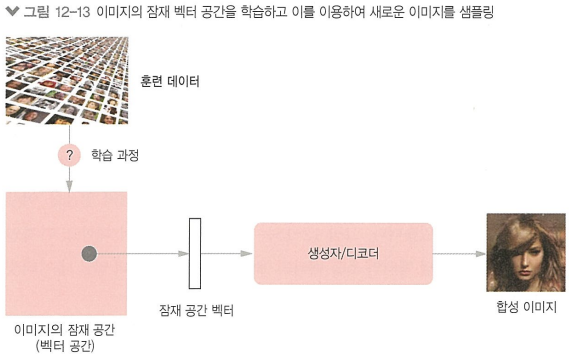
GAN: 매우 실제같은 이미지를 생성함, 잠재 공간은 구조적이거나 연속성이 없을 수 있음
VAE: 구조적 잠재 공간 학습에 뛰어남
* 개념 벡터: 원본 데이터의 흥미로운 변화를 인코딩한 잠재 공간 안의 한 방향
ex) 얼굴 이미지 > 웃음 벡터 발견 가능
* 변이형 오토인코더: 생성 모델의 한 종류로 개념 벡터를 사용하여 이미지를 변형하는 데에 아주 적절함
- 딥러닝과 베이즈 추론의 혼합
-전통적 오토인코더
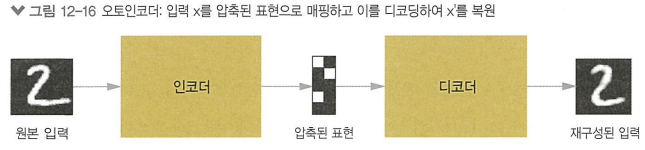
-변이형 오토인코더
> 입력 이미지를 고정 공간으로 압축하는 대신 이미지를 어떤 통계 분포의 파라미터로 변환
(인코딩과 디코딩 과정에서 무작위성 필요)
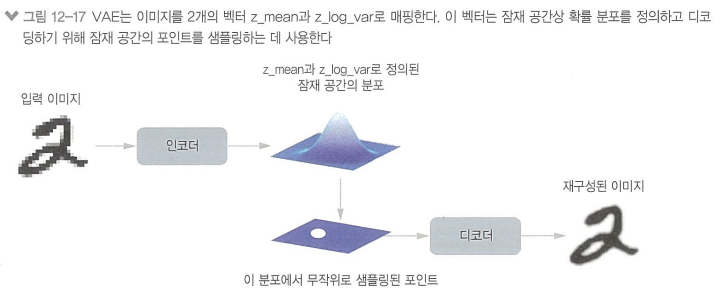
VAE 작동
1. 인코더 모듈이 입력 샘플 input_img를 잠재 공간의 두 파라미터 z_mean 과 z_log_var로 변환
2. 입력 이미지가 생성되었다고 가정한 잠재 공간의 정규 분포에서 포인트를 z를 z = z_mean + exp(0.5 * z_log_var) * eposilon 처럼 무작위로 샘플링 (epsilon은 작은 값을 가진 랜덤 텐서)
3. 디코더 모듈은 잠재 공간의 이 포인트를 원본 입력 이미지로 매핑하여 복원
2개의 손실 사용
1. 재구성 손실: 디코딩된 샘플이 원본 입력과 동일해지도록 하는 손실
2. 규제 손실: 훈련 데이터에 과대적합을 줄임
* 인코더 네트워크
latent_dim = 2
encoder_inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
encoder = keras.Model(encoder_inputs, [z_mean, z_log_var], name="encoder")
* 잠재 공간 샘플링 층
class Sampler(layers.Layer):
def call(self, z_mean, z_log_var):
batch_size = tf.shape(z_mean)[0]
z_size = tf.shape(z_mean)[1]
epsilon = tf.random.normal(shape=(batch_size, z_size))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
* 디코더 네트워크
latent_inputs = keras.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2D(1, 3, activation="sigmoid", padding="same")(x)
decoder = keras.Model(latent_inputs, decoder_outputs, name="decoder")
* 최대 풀링 대신 스트라이드를 사용하여 다운샘플링 함 (정보 위치 손실 막기 위함)



